 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMistake-Driven Learning in Text Categorization
Jun 09, 1997

Learning problems in the text processing domain often map the text to a space whose dimensions are the measured features of the text, e.g., its words. Three characteristic properties of this domain are (a) very high dimensionality, (b) both the learned concepts and the instances reside very sparsely in the feature space, and (c) a high variation in the number of active features in an instance. In this work we study three mistake-driven learning algorithms for a typical task of this nature -- text categorization. We argue that these algorithms -- which categorize documents by learning a linear separator in the feature space -- have a few properties that make them ideal for this domain. We then show that a quantum leap in performance is achieved when we further modify the algorithms to better address some of the specific characteristics of the domain. In particular, we demonstrate (1) how variation in document length can be tolerated by either normalizing feature weights or by using negative weights, (2) the positive effect of applying a threshold range in training, (3) alternatives in considering feature frequency, and (4) the benefits of discarding features while training. Overall, we present an algorithm, a variation of Littlestone's Winnow, which performs significantly better than any other algorithm tested on this task using a similar feature set.
Learning similarity-based word sense disambiguation from sparse data
Jul 11, 1996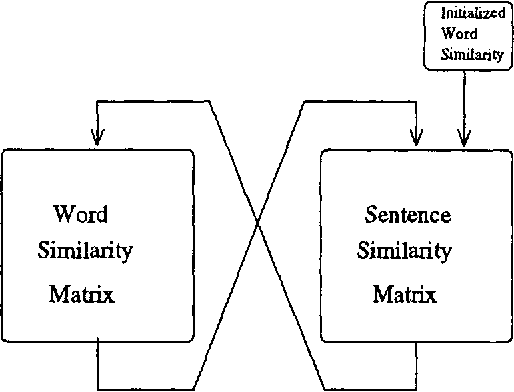
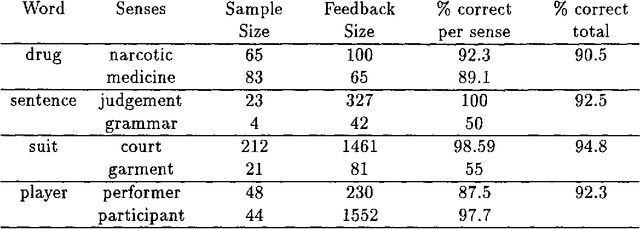
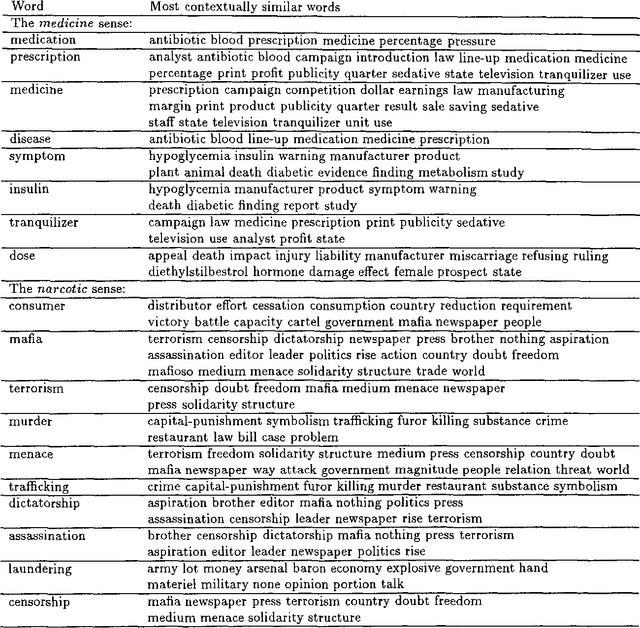
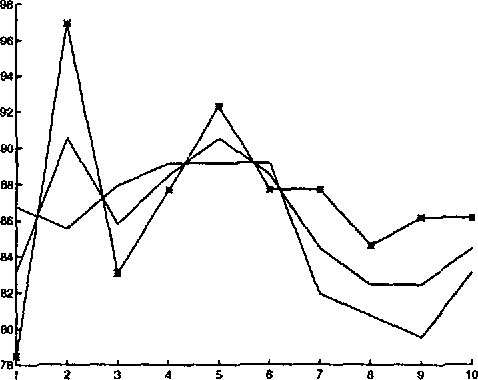
We describe a method for automatic word sense disambiguation using a text corpus and a machine-readable dictionary (MRD). The method is based on word similarity and context similarity measures. Words are considered similar if they appear in similar contexts; contexts are similar if they contain similar words. The circularity of this definition is resolved by an iterative, converging process, in which the system learns from the corpus a set of typical usages for each of the senses of the polysemous word listed in the MRD. A new instance of a polysemous word is assigned the sense associated with the typical usage most similar to its context. Experiments show that this method performs well, and can learn even from very sparse training data.